


Yapay zekâ modellerinin yetenekleri, Minecraft’ta gerçekleştirilen testlerle karşılaştırıldı.
Detaylar haberimizde…
Yapay zekâ modellerinin yeteneklerini değerlendirme konusunda geleneksel yöntemlerin yetersiz kaldığı bir dönemde, AI geliştiricileri, jeneratif AI modellerinin yeteneklerini daha yaratıcı yollarla test etmeye başladı. Bu gruplardan biri ise, Microsoft’a ait olan sandbox inşa oyunu Minecraft’ı kullanarak AI modellerini karşı karşıya getiriyor.
Minecraft Yapılarıyla AI Modellerini Yarıştıran Web Sitesi: MC-Bench
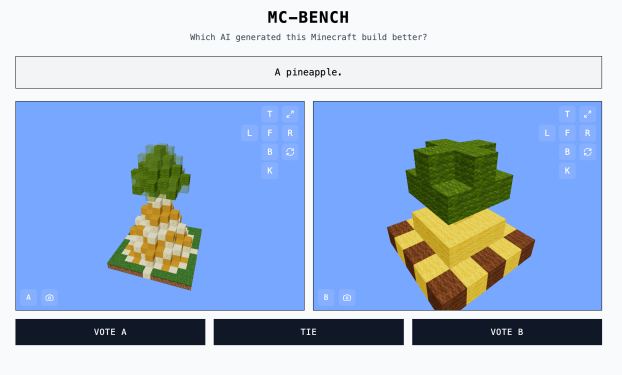
Minecraft Benchmark (ya da MC-Bench) adlı web sitesi, AI modellerinin birbirleriyle kafa kafaya mücadele etmesini sağlayan ve Minecraft yapılarıyla verilen komutlara nasıl yanıt verdiklerini test eden bir platform olarak geliştirildi. Kullanıcılar, hangi modelin daha iyi bir iş çıkardığını oylayabiliyor ve sadece oylama yaptıktan sonra hangi AI’nın hangi Minecraft yapısını inşa ettiğini görebiliyorlar.
Minecraft ile AI Modellerini Yarıştıran Lise Öğrencisi: Adi Singh
MC-Bench’i başlatan 12. sınıf öğrencisi Adi Singh, iki yapay zeka modelinin Minecraft yapı becerilerini karşılaştıran bir web sitesi oluşturdu. Kullanıcılar hangisinin daha iyi olduğuna dair oy kullanabiliyorlar.
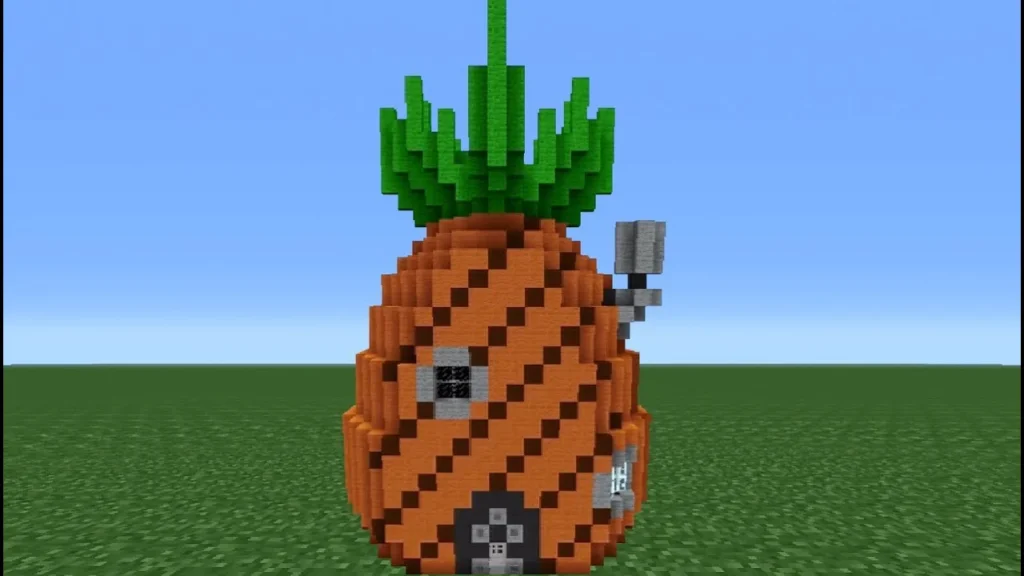
Minecraft’ın değerinin oyunun kendisinden çok, insanların bu oyuna olan aşinalığından kaynaklandığı belirtiliyor. Sonuçta Minecraft, tüm zamanların en çok satan video oyunu. Hatta oyunu oynamayanlar için bile, hangi bloklardan yapılan ananas figürünün daha iyi şekilde tasarlandığını değerlendirmek mümkün.
Singh, yaptığı açıklamada, “Minecraft, insanların [Yapay Zeka gelişiminin] ilerlemesini çok daha kolay görmesini sağlıyor. İnsanlar Minecraft’ın görünümüne ve havasına alışkın.” dedi.
MC-Bench Projesi: Yapay Zekâ Testleri İçin Yeni Bir Dönem
MC-Bench şu an sekiz gönüllü katkı sağlayıcıya sahip. Web sitesine göre, Anthropic, Google, OpenAI ve Alibaba, projeye benchmark komutlarını çalıştırabilmek için ürünlerini kullanmalarına yardımcı olmuş, ancak bu şirketler projeyle başka bir şekilde ilişkilendirilmemiş.
Singh, “Şu anda sadece GPT-3 dönemine ne kadar uzaklaştığımızı görmek için basit yapılar oluşturuyoruz, ancak ilerleyen zamanlarda uzun vadeli planlar ve hedef odaklı görevlerle devam edebileceğimizi düşünüyoruz,” açıklamalarında bulunuyor.
“Oyunlar, gerçek hayattan daha güvenli ve kontrollü bir ortamda ajans mantığını test etmek için iyi bir araç olabilir, bu yüzden benim için daha ideal hale geliyor.”
AI Değerlendirmelerinde Yeni Yöntem: Oyunlar ve Standart Testlerin Sınırları
AI test etmenin oldukça zor bir süreç olduğu bilindiği için, Pokémon Red, Street Fighter ve Pictionary gibi oyunlar, AI’yi değerlendirmek amacıyla deneysel araçlar olarak kullanılıyor.
Araştırmacılar, genellikle AI modellerini standart testlerle değerlendiriyor. Ancak bu testlerin çoğu, AI’nın eğitildiği yöntemlerle avantaj kazanmasına neden oluyor. Özellikle ezbere hafıza gerektiren veya basit çıkarımlar yapmayı içeren bazı problem çözme alanlarında modeller, doğal olarak başarılı oluyor.
AI Test Sonuçları: Yüksek Puan, Düşük Performans
Özetle, OpenAI’nin GPT-4’ün LSAT sınavında yüzde 88 puan alması, ancak “strawberry” (çilek) kelimesindeki R harflerinin sayısını bilememesi, AI’nın sınav performansının ne kadar anlamlı olduğunu anlamayı zorlaştırıyor. Aynı şekilde, Anthropic’in Claude 3.7 Sonnet modeli, yazılım mühendisliği için yapılan standart bir testte yüzde 62,3 doğruluk sağlasa da, Pokémon oynamada çoğu 5 yaşındaki çocuktan daha kötü sonuçlar veriyor.
Veri Toplama Olanağı
MC-Bench, teknik olarak bir programlama benchmark’ı olarak tasarlanmış, çünkü modellere, örneğin “Frosty the Snowman” (Karla Adam) ya da “temiz kumlu bir plajda hoş bir tropikal sahil evi” gibi yapıları yaratmak için kod yazmaları isteniyor. Ancak, çoğu kullanıcı için bir kardan adamın daha iyi görünüp görmediğini değerlendirmek, koda girmeye kıyasla daha kolay ve anlaşılır. Bu durum, projeyi daha geniş bir kitleye çekici hale getiriyor ve hangi modellerin sürekli olarak daha iyi puanlar aldığını izlemek için daha fazla veri toplama imkânı sağlıyor.
Bu puanların AI’nın ne kadar faydalı olduğu hakkında tartışmalar olsa da, Singh, bunların güçlü bir gösterge sunduğunu belirtiyor. Singh, “Şu anki liderlik tablosu, bu modelleri kullanma deneyimimle oldukça uyumlu, bu da birçok saf metin benchmark’ından farklı,” diyor. Ayrıca, MC-Bench’in şirketlere, doğru yönde ilerleyip ilerlemediklerini anlamalarına yardımcı olabileceğini ifade ediyor.
Testler, yapay zekâların tasarım ve yaratıcılık alanlarındaki yeteneklerini gözler önüne seren somut bir örnek oluşturuyor. Kullanıcıların bu platformlara etkileşimli şekilde katılması, yapay zekânın gelecekteki olasılıklarını keşfetmemize olanak sağlayan ilgi çekici bir deneyim sunuyor.
Derleyen: Eda Azap Öztemel




