

{kind=link}
- Animate Anyone, yeni “görüntüden videoya” teknolojisiyle dikkat çekiyor.
- Yeni video tekniğinde mankenler, kıyafetleri deforme etmeden, desenini kaybetmeden keyfi pozlar veriyor ve bir 2D anime figürü canlanıp dans ediyor.
- Teknoloji, şimdilik genel kullanım için fazla karmaşık ve hatalı olsa da yakın tarihte hızla gelişecek gibi duruyor.
Sanki hareketsiz görüntü deepfake’leri yeterince riskli değilmiş gibi yakında kendi fotoğraflarını internete koymaya cesaret eden herkesin oluşturulmuş videolarıyla karşılaşacağız gibi duruyor. Yeni video tekniği, Alibaba Group’un Akıllı Hesaplama Enstitüsündeki araştırmacılar tarafından geliştirildi. Bu, yaz aylarında etkileyici olan ancak artık kullanılmayan DisCo ve DreamPose gibi önceki video sistemlerinden ileri bir adım.
Animate Anyone’ın yapabileceği, eşi benzeri görülmemiş bir şey değil. Ancak “tuhaf akademik deney” ile “yakından bakmazsanız yeterince iyi” arasındaki o zor boşluğu aştığı kesin. Hepimizin bildiği gibi bir sonraki aşama, insanların gerçek olduğunu varsaydıkları için yakından bakma zahmetine bile girmeyecekleri “yeterince iyi” aşaması.
Bunun gibi görüntüden videoya modeller, satılık elbise giyen bir modelin, moda fotoğrafı gibi bir referans görüntüden yüz özelliği, desenler ve poz gibi ayrıntıların çıkarılmasıyla başlıyor. Daha sonra bu ayrıntıların çok az farklı pozlarla eşleştirildiği hareketle yakalanabilen veya başka bir videodan çıkarılabilen bir dizi görüntü oluşturuluyor.
Önceki modeller, bunun mümkün olduğunu gösteriyordu ancak pek çok sorun vardı. Örneğin, halüsinasyon bu sorunlardan biriydi çünkü model, kişi döndüğünde kolun veya saçın nasıl hareket edebileceği gibi makul ayrıntılar üretmek zorundaydı. Bu, pek çok tuhaf görüntüye yol açarak ortaya çıkan videoyu inandırıcı olmaktan uzak hâle getiriyordu. Şimdi ise Animate Anyone, mükemmel olmamış olsa da görüntüden videoya modelini ciddi anlamda geliştirdi.
Yeni modelin teknik özellikleri çoğu kişinin ötesinde. Ancak makale, modelin tutarlı bir özellik alanında referans görüntüyle ilişkiyi kapsamlı bir şekilde öğrenmesini sağlayan ve görünüm ayrıntılarının korunmasının iyileştirilmesine önemli ölçüde katkıda bulunan yeni bir ara adıma dikkat çekiyor. Temel ve ince ayrıntıların daha iyi korunması sayesinde oluşturulan görüntüler, üzerinde çalışılacak daha güçlü bir temel gerçeğe sahip oluyor ve çok daha iyi sonuçlar veriyor.
Video sonuçları, birkaç bağlamda sergileniyor. Mankenler, kıyafetleri deforme etmeden, desenini kaybetmeden keyfi pozlar veriyor ve bir 2D anime figürü canlanıp dans ediyor.
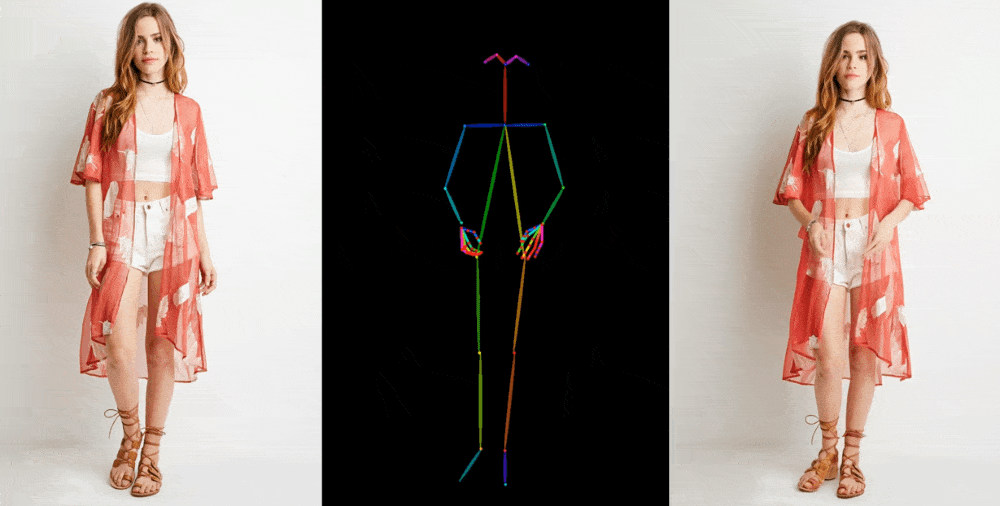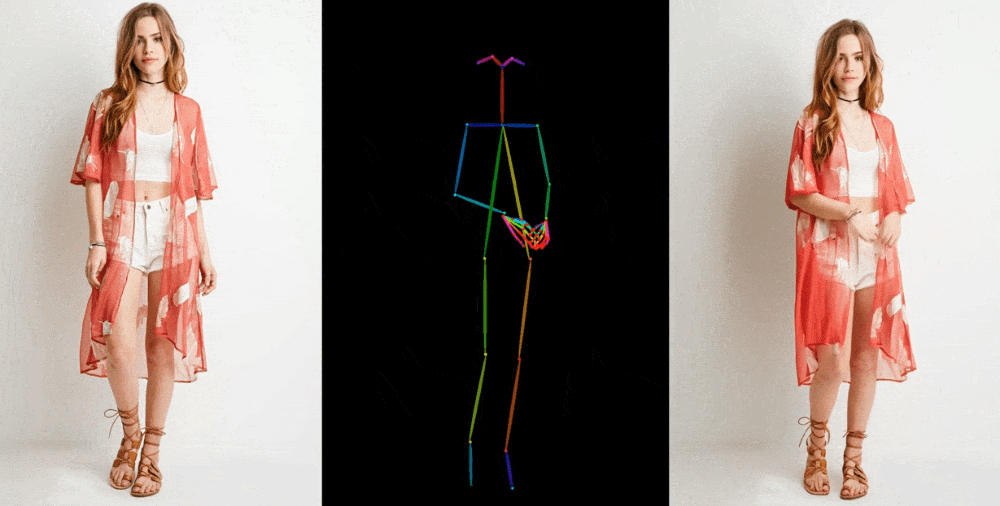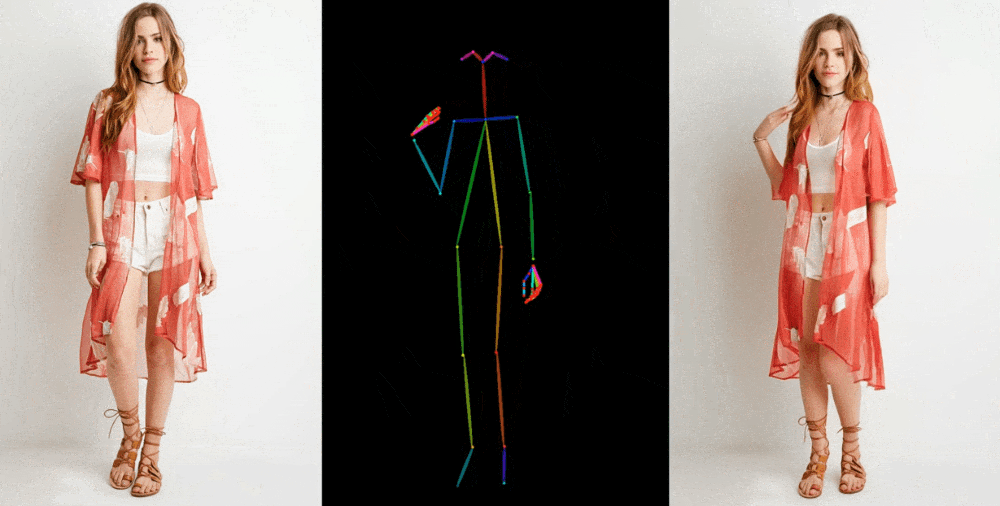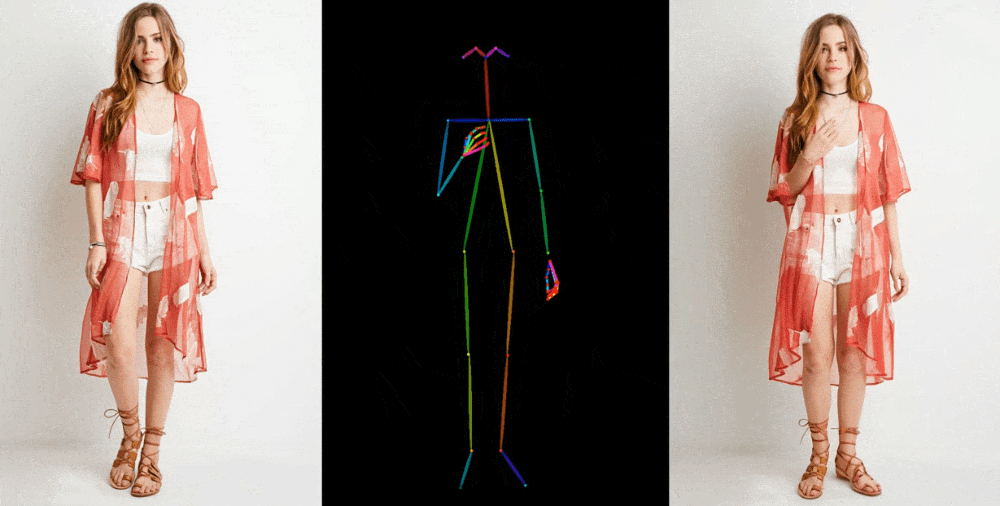
Bu figürler, özellikle üretken modeller için sorun yaratan gözler ve eller konusunda mükemmel olmaktan çok uzak. En iyi temsil edilen pozlar ise aslına en yakın olanlar. Örneğin, kişi arkasını dönerse model ona ayak uydurmakta zorlanıyor. Ancak bu, çok daha fazla eser üreten veya bir kişinin saçının rengi ve kıyafeti gibi önemli detayların tamamen kaybolduğu önceki teknolojiye göre büyük bir ilerleme.
Kötü niyetli bir aktörün ya da yapımcının tek bir kaliteli görüntünüzle size hemen hemen her şeyi yaptırabileceğini düşünmek rahatsız edici. Şimdilik teknoloji, genel kullanım için fazla karmaşık ve hatalı. Ancak yapay zeka dünyasında işler uzun süre bu şekilde kalma eğiliminde değil.
Ekip, kodu henüz kullanıma açmadı. Geliştiriciler, GitHub sayfalarına sahip olmalarına rağmen şunları yazıyor: “Demoyu ve kodu halka açık yayına hazırlamak için aktif olarak çalışıyoruz. Şu anda belirli bir yayın tarihi veremesek de lütfen hem demoya hem de kaynak kodumuza erişim sağlama niyetimizin kesin olduğundan emin olun.”
Derleyen: Fatma Ebrar Tuncel