

{kind=link}
Bilim insanları, AudioX adını verdikleri, metinler, video görüntüleri, resimler, müzik ve ses kayıtları gibi çeşitli veri kaynaklarını kullanarak yüksek kaliteli ses ve müzik parçaları üretebilen yapay zeka modelini geliştirdi.
Detaylar haberimizde…
Son yıllarda, bilgisayar bilimcileri metinler, görüntüler, videolar, şarkılar ve diğer içerikleri oluşturmak için çeşitli yüksek performanslı makine öğrenimi araçları geliştirdiler. Bu modellerin büyük bir kısmı, kullanıcılar tarafından sağlanan metin tabanlı talimatlara göre içerik oluşturmak üzere tasarlanmıştır.
Hong Kong Bilim ve Teknoloji Üniversitesi’ndeki araştırmacılar, yakın zamanda, metinler, video çekimleri, resimler, müzik ve ses kayıtları gibi çeşitli veri girişlerini kullanarak yüksek kaliteli ses ve müzik parçaları oluşturabilen AudioX adlı bir model tanıttılar. arXiv ön baskı sunucusunda yayınlanan bir makalede tanıtılan bu model, girdi verilerini aşamalı olarak gürültüden arındırarak içerik oluşturmak için “transformatör” mimarisinden yararlanan gelişmiş bir makine öğrenimi algoritması olan bir difüzyon transformatörüne dayanmakta.
Araştırmanın Arka Planı ve Amacı
Makalenin yazışma yazarı Wei Xue, Tech Xplore’a verdiği demeçte, “Araştırmamız yapay zekadaki temel bir sorudan kaynaklanıyor: Akıllı sistemler, birleşik çapraz modal anlayış ve üretimi nasıl başarabilir?” dedi. “İnsan yaratımı, farklı duyusal kanallardan gelen bilgilerin beyin tarafından doğal olarak kaynaştırıldığı sorunsuz bir entegre süreçtir. Geleneksel sistemler genellikle özel modellere güvenmiş ve modaliteler arasındaki bu içsel bağlantıları yakalayamamıştır.”
Wei Xue, Yike Guo ve meslektaşlarının yürüttüğü bu son çalışmanın temel amacı, birleşik bir temsil öğrenme çerçevesi geliştirmekti. Bu çerçeve, yalnızca belirli bir veri türünü işleyebilen ayrı modelleri birleştirmek yerine, tek bir modelin farklı modalitelerdeki bilgileri (yani metinler, resimler, videolar ve ses parçaları) işlemesine olanak tanıyacaktı.
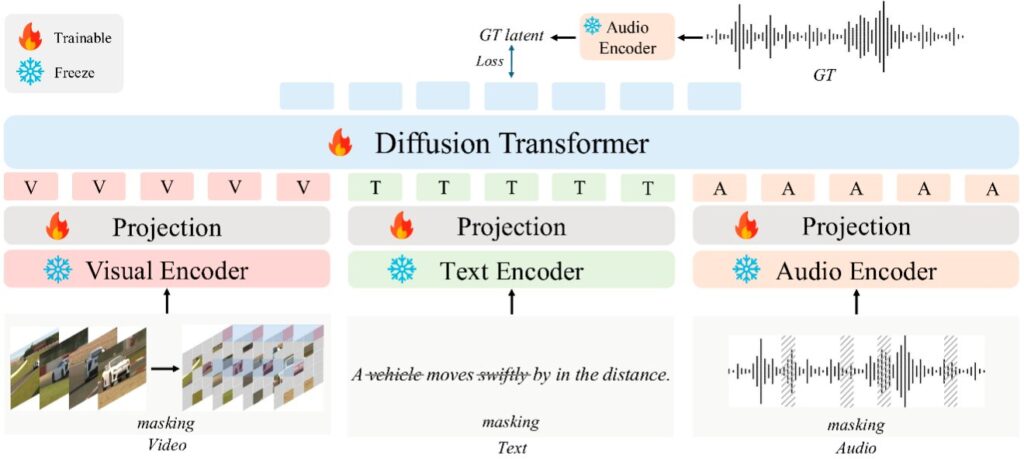
Xue, “Amacımız, yapay zeka sistemlerinin insan beynine benzer çapraz modal kavram ağları oluşturmasını sağlamak,” dedi. “Oluşturduğumuz model olan AudioX, kavramsal ve zamansal hizalama ikili zorluğunu ele almayı amaçlayan bir paradigma değişimini temsil ediyor. Başka bir deyişle, hem ‘ne’ (kavramsal hizalama) hem de ‘ne zaman’ (zamansal hizalama) sorularını aynı anda ele almak üzere tasarlandı. Nihai hedefimiz, gerçeklikle tutarlı kalan multimodal dizileri tahmin edebilen ve üretebilen dünya modelleri oluşturmaktır.”
AudioX Modelinin Yetenekleri
Araştırmacılar tarafından geliştirilen yeni difüzyon transformatör tabanlı model, girdi verilerini rehber olarak kullanarak yüksek kaliteli ses veya müzik parçaları oluşturabiliyor. Bu “herhangi bir şeyi” sese dönüştürme yeteneği, eğlence endüstrisi ve yaratıcı meslekler için yeni olanaklar sunuyor. Örneğin, kullanıcıların belirli bir görsel sahneye uyan müzikler oluşturmasına veya istenen parçaların oluşturulmasına rehberlik etmek için girdi kombinasyonlarını (örneğin, metinler ve videolar) kullanmasına olanak tanıyor.
Xue, “AudioX bir difüzyon transformatör mimarisi üzerine kuruludur, ancak onu farklı kılan şey çoklu modal maskeleme stratejisidir,” diye açıkladı. “Bu strateji, makinelerin farklı bilgi türleri arasındaki ilişkileri nasıl anlamayı öğrendiklerini temelden yeniden tasarlıyor.
“Eğitim sırasında girdi modaliteleri genelinde öğeleri gizleyerek (yani, video karelerinden yamaları, metinden belirteçleri veya sesten bölümleri seçici olarak kaldırarak) ve modeli eksik bilgileri diğer modalitelerden kurtarmak için eğiterek, birleşik bir temsil alanı oluşturuyoruz.”
AudioX Yeteneklerine Genel Bakış. Bu diyagram, Metinden Sese, Videodan Sese, Ses Boyama, Metinden Müziğe, Videodan Müziğe ve Müzik Tamamlama gibi çeşitli görevlerde AudioX’in çok yönlü yeteneklerini göstermekte. Model, çeşitli girdiler için bağlamsal olarak uygun ses üretmede güçlü performans sergilemekte.
AudioX, dilbilimsel açıklamaları, görsel sahneleri ve ses kalıplarını birleştiren, bu multimodal verilerin semantik anlamını ve ritmik yapısını yakalayan ilk modellerden biri. Benzersiz tasarımı, insan beyninin farklı duyular tarafından alınan bilgileri (yani görme, işitme, tat, koku ve dokunma) nasıl entegre ettiğine benzer şekilde, farklı veri türleri arasında ilişki kurmasına olanak tanıyor.
Modelin Avantajları ve Uygulama Alanları
Xue, “AudioX, çeşitli temel avantajlara sahip, şimdiye kadarki en kapsamlı herhangi bir-sese temel modelidir,” dedi. “İlk olarak, tek bir model mimarisi içinde oldukça çeşitlendirilmiş görevleri destekleyen birleşik bir çerçevedir. Ayrıca, çoklu modal maskelenmiş eğitim stratejimiz aracılığıyla çapraz modal entegrasyonu sağlayarak birleşik bir temsil alanı yaratır. Yeni derlenmiş koleksiyonlarımız da dahil olmak üzere geniş ölçekli veri kümelerinde eğitildiği için hem genel sesi hem de müziği yüksek kalitede işleyebilen çok yönlü üretim yeteneklerine sahiptir.”
İlk testlerde, Xue ve meslektaşları tarafından oluşturulan yeni modelin, metinleri, videoları, görüntüleri ve sesi başarılı bir şekilde entegre ederek yüksek kaliteli ses ve müzik parçaları ürettiği bulundu. En dikkat çekici özelliği, farklı modelleri birleştirmek yerine, farklı girdi türlerini işlemek ve entegre etmek için tek bir difüzyon transformatörünü kullanması.
Xue, “AudioX, tek bir mimaride, metin/video-sesten ses boyama ve müzik tamamlama gibi çeşitli görevleri destekleyerek, tipik olarak yalnızca belirli görevlerde başarılı olan sistemlerin ötesine geçiyor,” dedi. “Model, film yapımı, içerik oluşturma ve oyun gibi çeşitli potansiyel uygulamalara sahip olabilir.”
Çeşitli görevlerde nitel karşılaştırma. Kredi: arXiv (2025). DOI: 10.48550/arxiv.2503.10522
Gelecekteki Potansiyel ve Araştırma Yönleri
AudioX’in yakın gelecekte daha da geliştirilebileceği ve çok çeşitli ortamlarda kullanılabileceği düşünülüyor. Örneğin, film, animasyon ve sosyal medya için içerik üretiminde yaratıcı profesyonellere yardımcı olabilir.
Xue, “Bir film yapımcısının artık her sahne için bir Foley sanatçısına ihtiyacı olmadığını hayal edin,” diye açıkladı. “AudioX, yalnızca görsel çekimlere dayanarak otomatik olarak kar üzerinde ayak sesleri, gıcırtılı kapılar veya hışırtılı yapraklar oluşturabilir. Benzer şekilde, sosyal medya fenomenleri tarafından TikTok dans videolarına mükemmel arka plan müziğini anında eklemek veya YouTuber’lar tarafından seyahat vloglarını otantik yerel ses manzaralarıyla geliştirmek için kullanılabilir – hepsi isteğe bağlı olarak oluşturulur.”
Gelecekte AudioX, arka plan seslerinin oyuncuların eylemlerine dinamik olarak uyum sağladığı sürükleyici ve uyarlanabilir oyunlar oluşturmak için video oyunu geliştiricileri tarafından da kullanılabilir. Örneğin, bir karakter beton bir zeminden çimlere geçerken ayak seslerinin sesi değişebilir veya oyuncu bir tehdide veya düşmana yaklaşırken oyunun müziği kademeli olarak daha gergin hale gelebilir.
Xue, “Bir sonraki planlanan adımlarımız, AudioX’i uzun biçimli ses üretimine genişletmeyi içeriyor,” diye ekledi. “Dahası, multimodal verilerden yalnızca ilişkileri öğrenmek yerine, öznel tercihlerle daha iyi uyum sağlamak için bir takviyeli öğrenme çerçevesi içinde insan estetik anlayışını entegre etmeyi umuyoruz.”
Derleyen: Enis Yabar